
One of the issues we’ve come across in developing our new data quality tool is the sheer size of many of the data source tables. This makes a good method of filtering absolutely essential, both to break down the data into manageable chunks for analysis and to target rules for cleaning up that data (by specifying the values to which a given rule will be applied).
We wanted our filtering tool to be flexible and powerful, but also user-friendly and as easy to understand as possible. We’ve come up with a neat solution that encapsulates complex filtering options into three basic elements:
- a drop-down for selecting the type of filter
- a box for entering the filter text
- a button to turn case sensitivity on or off

The filter text is very flexible, because you can either enter an ordinary string of text or a regular expression – a special string of text which specifies a pattern of characters to be matched, rather than the exact text.
A few examples will show how powerful this can be in the context of data quality.
Weeding out irrelevant records
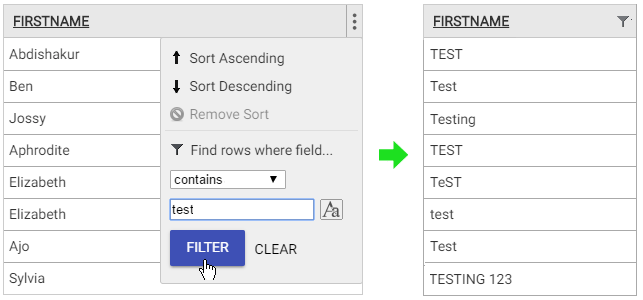
Customer files often contain some records that you don’t want to see when searching or analysing your data. These might be created internally for administration purposes and identifiable by a ‘begins with’ filter on the name or id field, matching text such as ‘admin’. Or they might be down to end-users not providing their real details, in which case a ‘contains’ filter on the name or email field, matching text such as ‘test’, might do the trick.
Searching for long values
If a field contains longer than expected values, this may indicate invalid data. For example, perhaps a field labelled ‘Title’ is intended to include values such as ‘Mr’, ‘Mrs’, ‘Dr’ or ‘Prof’, but some users have misunderstood it to mean ‘Job Title’. An ‘is of length’ filter with ‘>10’ in the text field would pick up these instances, so that they could be replaced with blank values.

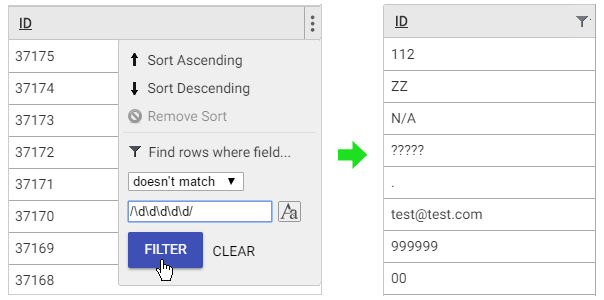
Validating IDs
ID fields often have a clear structure that can be checked using a filter. Let’s say our IDs should consist of five digits: a ‘doesn’t match’ filter with the regular expression ‘/\d\d\d\d\d/’ (‘\d’ stands for any numeric character) will find any invalid IDs that might lead to incorrect linking or duplication of customer records.
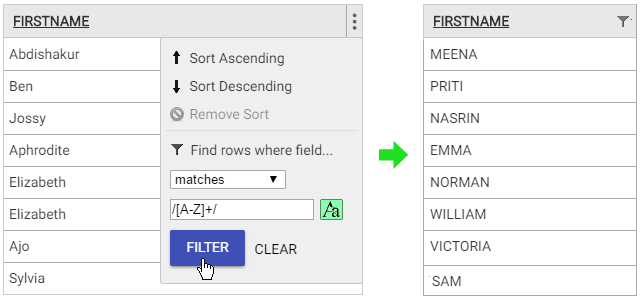
Correcting capitalisation
Especially where users have entered their own details, capitalisation issues often creep into name fields. We can find ones that start with a lower case letter by using a ‘begins’ filter with the regular expression ‘/[a-z]/’ and case sensitivity turned on. Or we can find ones that are all capitals by using a ‘matches’ filter with the regular expression ‘/[A-Z]+/’ and case sensitivity turned on. Either of these issues can then be fixed by applying a clean-up rule to convert to title case.
We’re confident that our filtering solution will allow efficient targeting of data clean-up rules within our data quality tool. And if the pattern matching examples above look like double Dutch to you, don’t worry – we’re also preparing clear and simple documentation!
