As we saw in last month’s article (“Why data quality matters”), the issue of data quality is becoming an essential point of basic good practice for all scholarly publishers. So, having noted the pitfalls of bad data and the benefits of good data, what practical steps can you take to improve things?
This is where the emerging business practice of ‘data governance’ comes into play. There’s a very good Wikipedia article about data governance, but in short it can be defined as “a set of processes that ensures that important data assets are formally managed … and that data can be trusted”. From a publisher’s perspective, the basic steps to put in place a data governance programme can be summed up as follows:
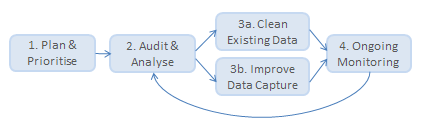
1. Plan & Prioritise. This is an essential first step in order to agree objectives, allocate resources, and gain management buy-in for the importance of good quality data as a business asset. Also, not all data is equal! So, it’s very important to assess how data is actually used, and from there to identify the most important data elements to audit and clean. For example, you’ll probably decide that Name, Address and Email details are a very high priority.
2. Audit & Analyse. The next step is to audit the quality of your existing data, which will be held in various different places (e.g. authors, subscribers, members, etc.) This allows you to profile your data and gain visibility of what’s good and bad. It will include various tests and checks, including blank vs populated fields, validation (of emails, countries, postcodes, etc.), finding outliers (unusually low or high dates and numbers), and so on.
3a. Clean Existing Data. Having identified the most important problem areas, the next challenge is to take steps to clean up your existing data. In some cases that can be automated (e.g. correcting a country of ‘London’ to ‘United Kingdom’) and in other cases that may require extra info from the customer (e.g. a missing email address), which you might plan to capture from them next time they log in (a technique known as “progressive profiling”).
3b. Improve Data Capture. The other side of data clean-up involves making improvements to the way data is entered in the first place (e.g. your online registration forms). If poor quality data is being entered, can extra checks be added at the point of data entry to prevent that happening in future? Those checks might include required fields, email validation, and so on.
4. Ongoing Monitoring. And of course, data clean-up isn’t a one-time task. Regular auditing, spot checks, and tracking reports over time will ensure that your data stays clean. Creating dashboards can be a useful way to define and track key data quality measures – to ensure that your data governance programme is having the desired effect.
If you’d like to discuss how DataSalon can help you with data quality and data governance, just contact us requesting further details.
